Deconvolution#
Usually, images acquired by a vision system suffer from degradation that can be modelled as a convolution. For example, some images present a camera shake effect (Fig. 114) or a blur due to poor focus (Fig. 115). The goal of deconvolution is to cancel the effect of a convolution.

Fig. 114 An example of motion blur (the parliament of Budapest shot by a camera).#

Fig. 115 Hubble’s view of Ganymede in 1996.#
The degradation phenomenon is modelled as in Fig. 116: The observed image \(y\) is degraded by the convolution with a PSF \(h\) and, possibly, by a noise \(b\) (considered to be additive).
The deconvolution computes a deconvolved image \(\widehat{x}\) from the observation \(y\). We will consider only linear methods, thus deconvolution comes to filtering by \(g\):
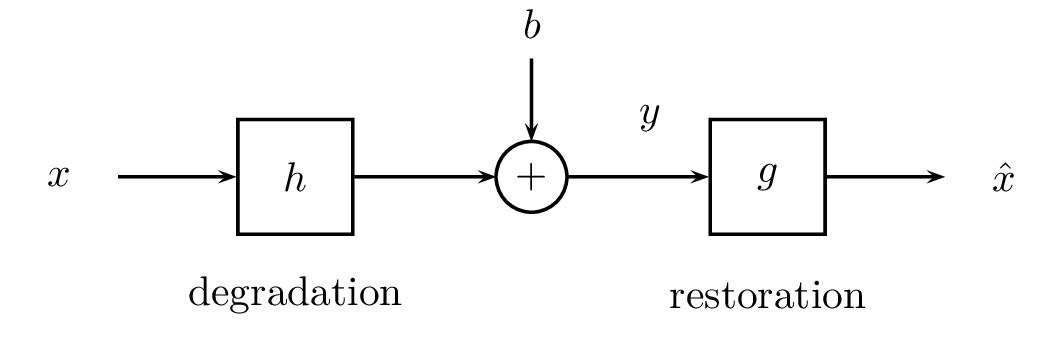
Fig. 116 Deconvolution model.#
Deconvolution needs a degradation model, thus having knowledge about both \(h\) and \(b\).
The PSF \(h\) can be estimated by observation, i.e. by finding in the image some factors to estimate \(h\). For example, a single point object in the image is \(h\). The PSF can also be estimated by experimentation by reproducing the observation conditions in a laboratory. So, the image of a pulse gives an estimate of \(h\). Finally, it is also possible to estimate the PSF from a mathematical model of the physics of the observation. Note also that some deconvolution methods estimate the PSF \(h\) at the same time as \(x\): these are called blind deconvolution methods (French: déconvolution myope).
Models for the noise have already been presented in chapter Denoising.
Inverse filter#
The inverse filter is the simplest deconvolution method. Since the degradation is modelled \(y = h*x + b\), then this equation becomes in the Fourier domain:
so we can write:
We obtain \(x\) by calculating the inverse Fourier transform of the previous expression:
As the noise (and therefore its spectrum \(B\)) is unknown, we can approximate the expression of \(x\) by cancelling \(B\) in the previous expression, and thus get the deconvolved image:
The result of the inverse filter applied on an image is given Fig. 117. The result is not usable, and yet the observed image is very little blurred with very little noise!

Fig. 117 Result of the inverse filter.#
The catastrophic result of the inverse filter is due to the fact of having considered the noise to be zero. Indeed, according to the definition of \(\widehat{x}\) and considering \(Y = HX + B\), then:
Thus, the deconvolved image \(\widehat{x}\) corresponds to \(x\) with an additional term which is the inverse Fourier transform of \(B/H\). The PSF \(H\) is generally a low-pass filter, so the values of \(H(m,n)\) tend towards \(0\) for high frequencies \((m,n)\). Because \(H\) is in the denominator, this tends to drastically amplify the high frequencies of the noise, and then the term \(B/H\) quickly dominates \(X\). This explains the result of Fig. 117.
One solution consists in considering only the low frequencies of \(Y/H\). This is equivalent to truncating the result given by the inverse filter by cancelling the high frequencies before calculating the inverse Fourier transform. The result of the deconvolution is much more acceptable, as shown by Fig. 118, although the result is still far from perfect (there are many variations in intensity around objects, such as tree trunks)…

Fig. 118 Result of the truncated inverse filter with very small noise.#
Wiener Filter#
Wiener filter, denoted by \(g\) (with Fourier transform \(G\)), applies to the observation \(y\) such that:
This filter is established in the statistical framework: the image \(x\) and the noise \(b\) are considered to be random variables. They are also assumed to be statistically independent. As a result, the observation \(y\) and the estimate \(\widehat{x}\) are also random variables.
The calculations are done in the Fourier domain for simplicity (since convolutions become multiplications). The goal of Wiener filter is to find the image \(\widehat{X} = \mathcal{F}[\widehat{x}]\) closest to \(X = \mathcal{F}[x]\), in the sense of the mean squared error \(\mathrm{MSE} = \mathbb{E}\left[(\widehat{X}-X)^2\right]\). Thereby :
where \(I\) is an image filled with 1. So:
where \(\cdot^*\) denotes the conjugate of the variables. Since the expectation \(\mathbb{E}\) is linear and only \(X\) and \(B\) are random variables, we can decompose the previous expression into four terms:
Since \(X\) and \(B\) are independent, then the covariances \(\mathbb{E}\big[X^*B\big]\) and \(\mathbb{E}\big[B^*X\big] \) are zeros. Moreover, \(\mathbb{E}\big[X^*X\big]\) and \(\mathbb{E}\big[B^*B\big]\) are the power spectral densities denoted as \(S_x\) and \(S_b\) (the power spectral density is the expectation of the square of the modulus of the Fourier transform). So the mean squared error simplifies into:
We look for the filter \(G\) that minimizes the MSE, or equivalently, that cancels the derivative of MSE:
Here we are, we get the expression of the Wiener filter \(G\)! 🥳 Finally, the deconvolved image is the inverse Fourier transform of \(GY\):
We can consider that the power spectral densities \(S_x\) and \(S_b\) are constant (for \(S_b\), it is necessary to assume white noise). Thus, the expression of the Wiener filter can be written
and the term \(S_b/S_x\) is replaced by a constant \(K\), which becomes the parameter of the method, to be set by the user.
Two remarks:
where \(H\) vanishes (typically in high frequencies), the problem of noise increase is no longer observed as with the inverse filter, since the inverse filter tends towards 0,
moreover, if the noise in the image is zero, then \(S_b = 0\) and Wiener filter comes back to the inverse filter:
\[ \widehat{x} = \mathcal{F}^{-1} \Bigg[ \frac{H^*}{|H|^2} Y \Bigg] = \mathcal{F}^{-1} \Bigg[ \frac{Y}{H} \Bigg] \]
The result of Wiener filter is presented Fig. 119: it is clearly much better than the inverse filter, even its truncated version!

Fig. 119 Result of Wiener filter (\(\lambda\) is set so that the estimation is the best in terms of MSE).#